Съвети за цифровизиране на печатно издание
Цифровизирането на книга (и изобщо на печатно издание) не е еднозначен процес и затова няма точна рецепта за изпълнението му. „Правилният“ метод зависи от това с какво оборудване разполагате, какви програми предпочитате да използвате, и най-вече от това, какво искате да получите като резултат. Затова този документ ще опише само основните насоки за правилно извършване на процеса, както и най-често допусканите грешки.
За да няма объркване, уточнявам още в началото — тук ще става въпрос само за действията, необходими за преобразуването на печатно издание (книга) в редактируем цифров вид, съвместим с „Моята библиотека“. Независимо от това, някои от съветите ще са приложими и при други задачи — например сканиране на илюстрована енциклопедия с цел пакетиране в PDF или DjVu.
И още нещо: съветите, описани тук, са само препоръки, а не твърди правила — сами решавайте дали да ги спазвате или не, но не се сърдете, ако отклонението от тях доведе до лош резултат. И както всички правила, и тези имат изключения.
Основните етапи при цифровизиране на книга са следните:
- Сканиране
- Разпознаване
- Корекция
Сканирането представлява заснемане страниците на книгата и записването им в компютъра във вид на картинка. За целта може да се използва скенер, цифров фотоапарат и изобщо всяко устройство, което може да осигури качествено заснемане на страниците (например Google използват специализирана цифрова видеокамера).
Разпознаването се извършва от специализиран OCR софтуер (от „Optical Character Recognition“ — „Оптично разпознаване на символи“), който разпознава текста от заснетите изображения и го преобразува във вид, удобен за редактиране — най-често в някой от разпространените текстови формати: TXT, HTM, RTF, DOC и т.н.
Корекцията представлява поправка на грешките, допуснати от OCR-програмата, например грешно разпознати думи, фалшиви препинателни знаци - най-често се появява „точка“ при наличие на петно върху картинката — и т.н. По време на този етап може да се извърши и допълнително форматиране на обработвания текст — например преобразуване в SFB-формат за директно публикуване в „Моята библиотека“ или поправка на стиловото оформление за да се получи документ, максимално близък до оригинала и т.н.
Съдържание
Кратки инструкции за абсолютно начинаещи
Ако никога не сте се занимавали с цифровизиране на печатно издание, опитайте! Това ще ви даде представа за основните неща, на чиято база по-късно ще се усъвършествате.
За опростяване на обясненията ще предполагаме, че разполагате със „стандартен“ комплект — компютър с Windows, скенер и инсталиран FineReader (в момента — началото на 2010 г. — последната версия е 10, но по-разпространена е 9-тата).
За експериментите изберете някое кратко произведение — например разказ или статия. За сканираща програма използвайте вградения интерфейс на FineReader. Разтворете книгата и я поставете върху скенера. Можете да сканирате страниците една по една или две наведнъж — зависи от размерите на книгата и скенера. Ако страниците не прилягат плътно до скенера, притиснете ги леко с ръка. Направете пробно сканиране (обикновено кръщават този режим „Preview“) и ако е необходимо, намалете областта за сканиране, така че да не губите време (и място на диска) за сканиране на празните области около книгата. След това сканирайте първата страница. Докато четящата глава на скенера се връща в изходна позиция, прелистете на следващата страница, сканирайте я, и така — докато не заснемете цялото произведение.
Следва разпознаването. Уверете се, че сте избрали правилния език за разпознаване (най-често — български) и стартирайте „четенето“ на всички страници. След приключване на процеса в дясната част на екрана ще получите текстовото представяне на заснетия текст. Можете да коригирате грешно разпознатите елементи още във FineReader, а можете да го запишете в желания от вас формат и да го коригирате с любимата си текстообработваща програма.
Забележка: Много версии на FineReader поддържат режим „Scan&Read“, т.е. програмата едновременно ще сканира и разпознава текста. Лично аз не го използвам; първо — защото накъсва процеса на сканиране, и второ — защото преглеждам предварително разпознатите блокове преди да стартирам процеса на разпознаването им.
Това е всичко. Честито, току-що цифровизирахте първия си текст!
Сега да „задълбаем“ малко по-навътре…
Сканиране
Сравнение на CCD и CIS-скенерите
Забележка: В този раздел са използвани изображения и цитати от статията „Нагледно сравнение на CCD и CIS-скенерите“.
В момента всички скенери, предлагани на пазара, са или CIS, или CCD. Какво означават тези буквички и какви са особеностите на двата вида скенери?


CCD (Charge-Coupled Device) скенерите използват оптична система от обектив и огледала, за да прехвърли изображението от сканирания обект към сензора.
CIS (Contact Image Sensor) скенерите — в приблизителен превод: „контактен сензор на изображения“ — директно прехвърлят изображението към сензора, без да използват допълнителна оптика.
Ето примерни сканове (300 dpi, сиво) с използване на CIS и CCD скенери, съответно със силен и среден натиск на книгата:


На тези картинки ясно личи основният недостатък на CIS-скенерите: невъзможността да фокусират на повече от 1–1,5 мм от стъклото. Това се дължи на липсата на оптика — името „контактен сензор“ говори само за себе си. За съжаление по-силният натиск върху книгата няма да компенсира този недостатък; сензорът при CIS-скенерите е много близо до стъклото и дори при най-лекото му огъване четящата глава може да „задере“ по стъклото и да наруши линейността на сканиране:

В този пример е сканирано успоредно (т.е. четящата глава е успоредна на редовете в текста), а проблемният участък е удебелен изкуствено, за да се открои.
CIS-скенерите имат още един недостатък — между съседните фотоелементи на сензора има малко, но съществено за сканирането разстояние. За да го направят колкото се може по-незабележимо, CIS-сензорите фокусират малко под стъклото; т.е. те винаги дават леко размит резултат (или ако повече ви харесва — „загладен“; в рекламите това се представя като преимущество). Тази характеристика е особено забележима в участъци с лоша фокусировка (както в примера със среден натиск върху книгата) и се проявява като неравномерни хоризонтални линии.
От друга страна, наличието на оптика в CCD-скенерите предизвиква друг дефект: различен ход на лъча (различно разстояние) при сканиране на изображение в центъра и по краищата. Този дефект се проявява само когато сканираното изображение се отдалечава от стъклото на скенера — забележете изкривяването на редовете до сгъвката в примера със среден натиск върху книгата. Изкривяването може да се минимизира, ако разположите книгата така, че сгъвката да е перпендикулярна на линията на сканиране и книгата да е разположена колкото се може по-близо до центъра:

Разбира се, при това разположение повечето книги няма да могат да се поберат изцяло на скенера и ще се наложи да се сканират страница по страница.
Още няколко сравнения: CCD-скенерите са по-големи, по-шумни и консумират повече енергия, поради което задължително работят само с външно захранване. CCS-скенерите са по-компактни, по-тихи и могат да се захранват само от USB-порта на компютъра. Смята се, че липсата на оптика в CIS-скенерите ги прави по-малко поддатливи към външни въздействия (т.е. по-трудно е да се развалят при небрежно обслужване), но стъклото при тях винаги е по-тънко от CCD-аналозите им. Също така се счита, че CCD-скенерите по-добре предават цветовете, а лампата им осигурява безпроблемна работа за поне 10'000 часа експлоатация, докато CIS-скенерите започват да губят яркост (около 30%) след няколкостотин часа работа.
Софтуер
Много хора отричат „директното“ сканиране с FineReader. Първо, по-старите версии (7 и 8) се опитваха автоматично да „поправят“ сканираното изображение (дори и при изключена опция!), в следствие на което се получаваха некоректни изображения, които не могат да бъдат поправени с нищо. Второ, всички версии на FineReader записват сканираните изображения в собствен формат, който не се разпознава от никоя друга програма и това прави невъзможно както допълнителната им обработка преди разпознаване, така и безопасното им изпращане на друг човек. Разбира се, FineReader има възможност да експортира само сканираните картинки в някой от стандартните формати (между другото, тази възможност е неизвестна за повечето потребители и те продължават да изпращат цели пакети с проекти на FineReader, вместо само картинките), но той експортира вече преработените изображения, а не оригиналните сканове. (Забележка: Възможно е това да не е вярно за версия 10 — нямам достоверна информация по въпроса.)
Специалистите препоръчват за сканиране да се използва външна програма, поддържаща „пакетно“ сканиране (т.е. настройвате веднъж параметрите за сканиране, след което само прелиствате книгата и натискате един бутон, а програмата автоматично номерира изображенията). Също така се препоръчва да не правите никакви корекции на изображението чрез драйвера на скенера — като например яркост, контраст, заглаждане и т.н., — а да записвате „суровия“ скан. Разбира се, това не винаги е разумно — например при книга със силно пожълтели страници е желателна лека корекция на параметрите, така че да се получи по-контрастна страница.
Разделителна способност
Минималната допустима разделителна способност при сканиране на текст с цел разпознаване е 300 dpi. Текст, сканиран с по-ниска разделителна способност може и да ви изглежда четим, но програмата за разпознаване няма да се справи с него. Ето пример на текст, сканиран със 150 dpi:

Забележете липсващите участъци в буквите „е“ и „д“ — най-вероятно OCR-програмата ще ги разпознае като „с“ и „ц“. По-нататък в същия текст има букви „и“ и „н“ с липсваща средна чертичка, което прави еднозначното им разпознаване напълно невъзможно.
Книги, набрани с по-малък шрифт (10 pt и надолу), трябва да се сканират с 600 dpi. Ако използвате по-ниска разделителна способност, ще получите нещо подобно на горния пример — загуба на по-тънките линии.
Няма смисъл да сканирате книга с „нормален“ размер на шрифта с повече от 300 dpi — само ще изхабите място на диска, а качеството на разпознаването няма да се подобри. Даже напротив — при такива изображения FineReader често разпознава запетаите като цифрата 4 в долен индекс, а кавичките — като 44 в горен индекс. Затова, ако сканирате например детска книжка с основен шрифт 16 pt и нагоре, спокойно можете да сканирате с 200 dpi.
Цветност
Никога не сканирайте в черно-бял режим! В противен случай ще получите изображение, в което основният фон на страницата е представен с миниатюрни точки, а всяко по-тъмно петно — в плътно черен цвят:

Това е част от реален скан, предложен за разпознаване. Ако си поиграете с настройките на контраста, можете да получите малко по-качествено изображение, като например:

Затова — сканирайте само в нива на сивото. По всяко време можете да преобразувате сивата картинка в черно-бяла, при това — с по-добри алгоритми от използваните в драйвера на скенера или във FineReader, но обратното не е възможно — сканове като в двата горните примера не могат да бъдат почистени безопасно и еднозначно.
Изключение от правилото: можете да получите отлични резултати при ч/б сканиране, ако книгата е отпечатана на бяла, качествена хартия, с офсетов печат с плътни тъмни букви с контрастни краища. Досега не ми се е случвало да сканирам такава книга. Разбира се, ако планирате сам да покриете целия цикъл на обработката и по някаква причина скенерът ви работи по-бързо в черно-бяло, отколкото в сиво, можете да поекспериментирате с настройките и да получите сравнително прилични (по вашите критерии!) сканове.
Формат
Записвайте сканираните изображения в TIFF — за сивите и цветните картинки използвайте LZW или ZIP-компресия, а за черно-белите (например вече обработени с външна програма картинки) използвайте CCITT G4. Някои сканировчици записват некомпресирани TIFF-ове, което е напълно излишно и води единствено до загуба на дисково пространство — форматът TIFF записва изображенията без загуби, така че спокойно можете да използвате всякакви методи за компресия, които предоставя програмата за сканиране.
В никакъв случай не записвайте сканиран текст в JPG-формат! Този формат е идеален за пълноцветни изображения (например фотоснимки), но е напълно неподходящ за страници с текст. Основната причина за това е, че JPEG-кодирането е кодиране със загуби, което в случая с книгите се проявява като шум около буквите:

По принцип нивото на загубите при кодиране на JPEG-а може да се настройва, но почти всички драйвери за сканиране не предоставят на потребителя такава възможност и сами определят допустимото ниво, което води до появяване на по-голям шум около буквите.
И още — не пакетирайте сканираните изображения в PDF! Първо, така ще блокирате всякаква възможност за по-нататъшна обработка — тя ще бъде възможна само чрез извличане на страниците от PDF-а, което в общия случай не води до получаване на оригиналните сканирани изображения. Второ, така губите или място на диска, или качество на изображенията — в зависимост от това дали сканиращата програма използва PDF-а само като контейнер на TIFF-овете, или ги преобразува до стандартния за PDF формат JPG, чиито недостатъци бяха разгледани по-горе.
Други съвети
- Ограничете областта за сканиране. Няма нужда да оставяте прекалено големи полета около книгата — така губите както място на диска, така и време за сканиране, — но е опасно да ограничавате сканираната област само до наличния текст — така при най-малкото отклонение от настроения размер страницата ще „излезе от кадър“. Подравнете книгата откъм късата страна на скенера, където паркира четящата глава, направете пробно сканиране („Preview“), след което ограничете областта за сканиране до външните контури на книгата.
- Докато прелиствате страниците, контролирайте чистотата на стъклото на скенера. Там често попадат косми или големи хартиени прашинки от книгата, които в последствие пречат на разпознаването.
- Не е задължително да затваряте капака на скенера, за да сканирате. Той е предвиден за по-точно притискане на единични листове, а не на цяла книга. Оставете го отворен и сканирайте спокойно. Все пак внимавайте да няма ярка директна светлина към стъклото на скенера — има наблюдения, че CIS-моделите са чувствителни към интензивността на външното осветление.
- Ако сканиращата програма разрешава, винаги записвайте страниците с имена, съдържащи един и същ брой цифри в номерата, т.е. вместо „Image 1.tif“, „Image 2.tif“… „Image 10.tif“ и т.н. използвайте „Image 001.tif“, „Image 002.tif“… „Image 010.tif“ и т.н. Разбира се, най-компактно ще е да използвате само цифри — „0001.tif“, „0002.tif“… Проблемът е, че различните програми (и операционни системи) нееднозначно сортират файлове, именовани по първия начин и в резултат можете да получите книга с разбъркани страници. Ако сканиращата програма няма такава възможност, изберете си някоя програма за пакетно преименуване на файлове („Rename Master“, „Bulk Rename“ и т.н.) и след като приключите сканирането, приведете имената в нормален вид.
- След като приключите сканирането проверете дали не сте пропуснали страници! Много лесно можете да прелистите две страници вместо една, особено при масово използваната напоследък хартия. Така че сравнете броя на сканираните изображения с разликата в номерата на последната и първата сканирана страница (евентуално разделен на две, ако сте сканирали по две страници наведнъж). Ако се получи разлика, значи сте пропуснали да сканирате страница (или сте сбъркали сметките :-). Пример: сканирали сте двойни страници — първият скан е на стр. 2-3; последният — 218-219. Изваждате първия номер от последния (218-2) и получавате 216; делите на две защото сте сканирали двойни страници (получавате 108) и добавяте единица, за да включите и двата крайни номера (резултат: 109). Ако в папката със сканирани изображения има по-малко от 109 файла, значи сте пропуснали да сканирате страници. При сканиране на единични страници методът на пресмятане е същият, като пропуснем деленето на две.
- Контролирайте резултата още докато сканирате. Не оставяйте страници, в които има размазване на текста около сгъвката (най-често се получава при CIS-скенери, които не могат да фокусират на повече от милиметър-два над стъклото), накъсани изображения (поради движение на книгата по време на сканиране) и изобщо — всякакви дефекти, които ще доведат до невъзможност за разпознаване на текста:
 Размазване на текста до сгъвката
Размазване на текста до сгъвката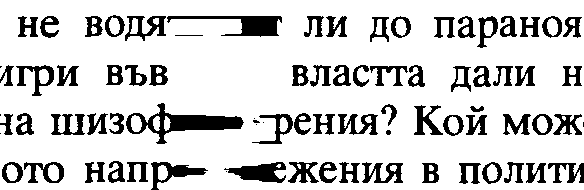 Накъсване на текста
Накъсване на текста
- Запазете оригиналните сканирани изображения до приключването на цялостната обработка на книгата (и дори малко след това). Винаги можете да ги изтриете, но ако потрябват (случва се!), едва ли ще ги сканирате отново.
- Ако сканирате цветни изображения и забележите „просветване“ на изображението от другата страна на страницата, поставете черен лист хартия под текущата страница.



Разпознаване
По този въпрос могат да се кажат много малко неща. Основният принцип е: „Не разчитайте на чудеса“. Програмите за разпознаване на текст се справят много добре със задачата си (понякога дори отлично ;-), но често допускат грешки. Тук ще изброя само няколко съвета за FineReader:
- По възможност използвайте английския интерфейс на програмата. Откакто „Давид холдинг“ спряха поддържката на FineReader за България (около версия 7) качеството на преводите в българския интерфейс е такова, че сякаш са правени с Google Translator. Така няма да се чудите какво означава съобщението „Действието не може да бъде ненаправено. Да продължа ли?“ или параметъра „Разлики в правилното изображение“ (в оригинал — „Deskew image“).
- Подберете внимателно параметрите при зареждане на сканираните картинки. Всяка включена ненужна опция забавя значително обработката на изображенията; например ако страниците са ви ориентирани правилно, няма нужда да включвате „Автоматично определяне ориентацията на страницата“. От друга страна, липсата на необходима обработка може да доведе до пълна невъзможност за разпознаване на страницата — например при зареждане на леко завъртяна страница с изключена опция „Изправяне на страница“ („Deskew“).
- Вместо директно да разпознавате заредените страници, можете да извършите това на два етапа — първо да стартирате разпознаването на областите (частите от страницата, съдържаща текст или илюстрация; освен чрез менюто това действие може да се стартира с клавишната комбинация Ctrl+Shift+E), след което да прегледате всички страници и да поправите неправилно определените области и едва тогава да пуснете разпознаването им. По този начин ще елиминирате два проблема: 1. Колонтитулът понякога се разпознава като част от основния текст, а не като отделен елемент; ако не го коригирате, той ще се появява навсякъде в експортирания текст, независимо от формата. 2. Ако областта с текст е по-широка отколкото е правилно (програмата е прихванала някое петно от хартията и е увеличила областта, за да го обхване), тогава редовете от тази област почти винаги ще се разпознаят като самостоятелни параграфи и при корекцията ще трябва да ги сливате ръчно. Много хора не знаят за тази възможност и затова директно стартират разчитането на страниците, след което ги обхождат и проверяват разпознатите области, а накрая пускат отново разпознаването на коригираните страници.
- И двата проблема, описани в предишната точка, се поправят много по-лесно с една сравнително неизвестна функция на FineReader — „Анализ на оформлението в текущата област“. Използвам я толкова често, че съм назначил клавишната комбинация Ctrl+D за съкратеното й извикване. При възникване на първия проблем (колонтитул като част от основния текст) в 80% от случаите е достатъчно да изберете областта (ако вече не е избрана, разбира се) и да стартирате тази функция — FineReader сам ще разбие областта на две — колонтитул и основен текст. Ако не успее, ще трябва ръчно да свалите горната граница на текста така, че да прескочи колонтитула. При втория случай (прихващане на петно встрани от текста) трябва да преместите съответната граница (отляво или отдясно) така, че да прескочи петното, но при това действие възниква следния проблем: Ако оставите твърде голямо бяло поле, редовете ще се разпознаят като отделни параграфи, а ако опитате ръчно да поставите възможно най-малкото поле, рискувате да отрежете част от текста, при което той ще се разпознае неправилно. Тук отново идва на помощ анализиращата функция — след като преместите границата зад петното, просто я стартирайте и FineReader сам ще ограничи белите полета до допустимия минимум.
- Ако книгата съдържа много малко текст на латиница (десетина думи), не разпознавайте на няколко езика едновременно (напр. „Български + Английски“), а само на български; по-късно ръчно ще поправите неправилно разпознатите думи. В противен случай ще получите голямо количество думи на латиница (напр. „Ho“, „My“ и т.н.), които са почти невъзможни за откриване, а при четене с шрифт, в който има разлика в начертанията на латиницата и кирилицата, визуалният ефект е доста неприятен. Нещо повече — при разпознаване на няколко езика едновременно FineReader замества дори единични букви в българска дума със съответния им графичен аналог в латиницата!
- Внимателно проверете параметрите и при експортиране на вече разпознатия текст във външен файл. Ако не разбирате тези параметри — питайте! Никой нормален редактор няма да коригира текст, който е записан с включена опция „Запазване на новите редове“ — кой ще се наеме да изтрие ръчно около 50'000 фалшиви нови реда?
- При експорт на текст винаги използвайте UFT-8 кодировка. Ако запишете файл със стандартна (ANSI) кодировка, почти със сигурност ще унищожите много от специалните символи, които са разпознати правилно — най-вероятно ще се заместят с квадратче или въпросителен знак.
Корекция
И по тази тема могат да се кажат много малко общи неща — конкретните схеми зависят от това, с каква програма предпочитате да извършвате корекцията на разпознатия текст. Тук общият принцип е следният: Разпознатият текст трябва да се изчете внимателно и да се поправят всички открити грешки. Сравнението с оригинала (книгата или сканираните изображения) е не само желателно, но и задължително — има много проблеми, които не могат да се открият само чрез четене. Тук ще опиша някои от по-сериозните проблеми в разпознатия текст, на които трябва да се отдели специално внимание при корекцията:
- Един от най-големите проблеми на FineReader е неправилното определяне края на параграфите. Това предизвиква както разкъсване на текст (разпознаване на един параграф като няколко), така и залепване (разпознаване на няколко поредни параграфа като един). Неправилно разкъсване се получава и в случаите, когато изречение от даден параграф свърши точно в края на листа, но параграфът продължава на следващата страница — това лесно се разпознава по липсата на отстъп в началото на новото изречение. Около 70% от тези проблеми могат да се открият само чрез изчитане, но за останалите 30% е необходимо сравнение с оригинала.
- Друг постоянен проблем на FR е разпознаването на главно „Ф“ като малко. Нещо повече — ако в средата на параграф дадено изречение започва с главно „Ф“, той го разпознава като малко и поправя предшестващата го точка на запетая. Затова трябва да обръщате по-специално внимание на думи с „ф“, и на препинателните знаци преди тях.
- Много грешки се получават и при разпознаване на наклонен текст. Повечето от тях се изразяват в грешно разпознати букви, които се откриват сравнително лесно, но най-сериозният проблем е, че наклоненият въпросителен знак почти винаги се разпознава като удивителен. Затова отделяйте по-специално внимание при проверката на наклонен текст, и особено на препинателните знаци.
- Добра идея е да извършите начална редакция на разпознатия текст още във FineReader — чрез вградения му редактор. Така ще можете „на място“ да проверите всички неуверено разпознати символи (които FR оцветява със синьо-зелен цвят) и при необходимост да ги поправите. А ако включите показването на невидимите символи (в случая ни интересува символа за параграф), ще можете да проверите и съответствието на новите редове. Имайте предвид обаче, че FR не винаги експортира точно редактирания текст — например във вградения редактор разстоянието между началното тире в пряката реч и текста се изобразява като табулатор, но при експортиране в HTML се преобразува в непрекъсваем интервал. При експорт в DOC или RTF пряката реч често се форматира като списък с водещи тирета (особено при къси изречения); ако преобразувате такъв документ в текстов файл, тези тирета ще бъдат изгубени. Затова — проверете особеностите при експортиране в предпочитания от вас формат и тогава се заемайте с поправки на текста.
- Друга интересна особеност на FineReader е, че той сравнява разпознатите думи с вградения си речник. Затова при разпознаване напр. на името „Крис“ в 95% от случаите ще получите „Крие“ — дори когато сканираното изображение е кристално чисто. Аналогично е и положението при пренесени думи, в които и двете части са смислени думи (напр. „при-ход“) — в повечето случаи тирето няма да бъде разпознато като меко тире (което може да бъде премахнато автоматично при експортиране), а като нормален дефис.